Training AI Night Vision

An introduction to key terms:
- AI: Artifical Intelligence. A smart computer program.
- AI Model: A program built to complete a task after learning about it.
- COCO is like a picture book that shows what a car and person looks like to teach AI.
- YOLO is the name of an AI model. It labels everything it sees in a photo.
AI has emerged, seemingly, out of no where, heralded as a silver bullet to our problems. As an emerging technology, I incorporated it into the two cameras at the front of my property to research the topic. However, I quickly noticed a flaw: I would not be notified of parcel deliveries after dusk. A flaw in need of fixing. The great minds behind YOLO and COCO have achieved incredible feats; however, many products are designed in an ivory tower, detached from real-world complexities.
Engineers achieving tolerances thinner than a strand of hair often find comfort inside this tower of ideal circumstances. It stands to reason that they could be oblivious to what lies beyond their walls. For instance, it would be easy for a person to overlook scenarios such as: jamming an ATM with paper-clipped cash, slamming drawers carelessly, or a bird gracing a newly installed product with droppings. All of these scenarios require foresight and robustness.
One such oversight that I noticed is: COCO primarily consists of well-lit images taken during the daytime with high-quality cameras free of blurry details–perfect photos. Naturally, this makes complete sense from a teacher’s standpoint. Who would want to spend hundreds of hours using blurry photos for a research baby named: “Drunk Vision AI”?
I applaud those at the frontier of AI development and enjoy reading their work. However, I am not in the market for an AI model well versed at counting a crowd of 70 at a subway station. Living in a quiet, American neighborhood with occasional visitors, I dedicated a year to tailoring an AI specifically for this setting, ensuring it performs effectively at any time of day.
Living beyond the confines of the ivory tower, I am subject to a fundamental truth of the natural world: the greatest obstacle to any endeavor is of course the budget constraints set by our significant other. To see what went wrong, I reviewed the video footage of my budget-friendly cameras to unearth the challenges that needed to be addressed.
Ghosting
Ghosting: A, very real, person doesn't obscure details such as the truck bed or wheel
It turns out Hollywood wasn’t entirely wrong: video cameras indeed have the ability to show us ghosts.
But how can a solid object fail to obscure the view of what lies behind it? Cameras struggle to see in the dark, so it allows itself more time to soak in light before it finalizes a still image for the video.
Imagine a car moving down the road and we keep our eyes locked at one point ahead. In this spot, the camera saw the road most of the time and the car just briefly as it zipped by. The camera must fit all of this info into a single picture that will eventually make up a video. The result is a blend–road and car–creating what appears to be a ghost.
These ghosts were a challenge for the AI to identify. To address this, I implemented a two-step training regimen.
Step 1) Add difficult to identify images to teach the AI model.
Step 2) The AI model uses this new information and occasionally made mistakes. I tell the AI that these mistakes are wrong to teach it further, a process known as “hard negative mining.”
Afterward, I would return to step one, pushing the limits into more challenging territory. This would result in additional incorrect guesses in step two. This teaching cycle is repeated many times.
About 2,000 images later, I decided to compare my results to Ultralytics’ latest model–YOLO version 11 (YOLO11).
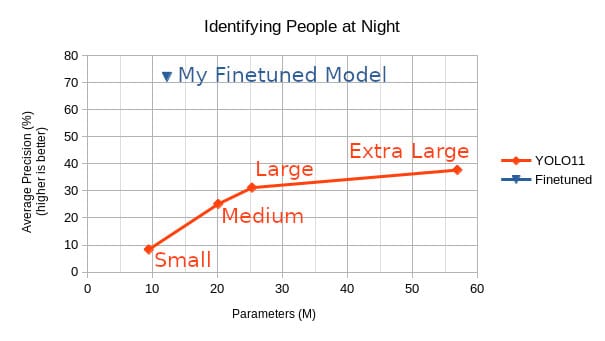
My model is on the smaller side–a low number of parameters. More parameters is akin to a larger brain with greater learning potential, though the benefits taper off as the size grows. However, far more important to an AI’s effectiveness is the architecture and learning materials used, though the former won't be covered on this brief overview.
A Look at some of the Test Results
To give them a fair shake, I evaluated the models on images they have never seen before. Nighttime poses the only challenge, so I am using exclusively low-light imagery to test several models.

Security systems generally only report seeing a person if the confidence level is above 50% to ensure nothing is missed when its time to review. This means that the small model above would have reported no people in the above image. All of the YOLO models fail to see the head of the person above.

I didn't expect all 5 to cross the finish line so easily in the above image.

- Small: The only "person" it reported was a bush, albeit with low confidence.
- Medium: Saw 2 people but lacked confidence.
- Large: Didn't see the head of the person but was the only of the YOLO family confident in itself.

I have seen my model detect people half this size during the day, but I was surprised it could identify this person despite being partially obscured by a vehicle. It failed to see the arm to the left though.
My model has impressed and even surprised me. I am truly pleased with its performance. Truthfully, the most rewarding part was hearing my client's enthusiasm once they noticed significant improvement from my quick update.
Key Insights
AI training
- My model excels with images at my home, because it has seen the same trees, cars, and sidewalk hundreds of times and knows these are not people.
- When teaching a model new information, it could regress by forgetting what it previously learned. There are a few techniques to prevent this.
- Try to be aware of biases introduced. For example, many people along my sidewalk are tall enough to have their face be blocked by the tree branches. Once the AI saw many of these images, it thought tree branches were apart of a person's face. For a time, my model would see a shorter person and think that the top of their head is further up in the branches by mistake.
- I tend err on the side of caution:
- the risk of adding one potentially confusing photo could have a significantly greater negative impact compared to the minor improvement it might bring.
- I didn't train the AI on unusual circumstances such as spider webs; because, it is flexible enough to extrapolate from its existing knowledge onto the fringe of life.
Improving camera performance at night
- Look for a setting named "exposure time" or "shutter time" and incrementally decrease the time, ensuring the image doesn't become too dark. (This setting controls how long the camera waits to soak in light before capturing an image.) Adjusting between 1/50th of a second to 1/150th is doable, the former being more conservative.
- Check if turning on the following improves low light performance.
- HLC (High Light Compensation)
- BLC (Back Light Compensation)
- WDR (Wide Dynamic range)
- Adjust the above first, then try increasing contrast or brightness just slightly.